爬虫开发笔记之cookies池系统设计
开发爬虫时,我们总希望目标网站反爬策略不足,一气呵成写好爬虫代码并部署运行,然而“理想很丰满,现实很骨感”,在爬虫大行其道的今日,稍微优质一点的信息类网站一般都会采取一定程度的反爬措施。不然小公司的服务器哪里扛得住各路爬虫orz.....不过,对于爬虫开发者来说,自然是“道高一尺,魔高一丈”,今日就简单聊聊反反爬方案——cookies池系统。
什么是cookies池
用于维护多条目标站点的有效cookie以便爬虫获取使用的服务(类似IP池)。
为什么需要设计cookie池
- 目标站点要求登录才能访问(如:知乎、淘宝、facebook, etc.)
- 单账号会受到访问频率限制(多账号管理)
- 模拟登录逻辑复杂 (将模拟登录单独做成服务)
- 登录脚本采用不同编程语言开发(如:node.js的puppeteer, javascript的cypress)
- 一些第三方库不支持同一种语言的不同版本(如:zheye对python3.6和python3.7)
cookie池的优点
- 服务分离:多语言开发,类似微服务的理念。
- 组件分离:比如redis可以换成mysql、Kafka等。
- 各个服务分别部署:防止网站变化导致爬虫宕机。
cookie池系统设计架构
一个简易的cookie池系统架构如下图所示:
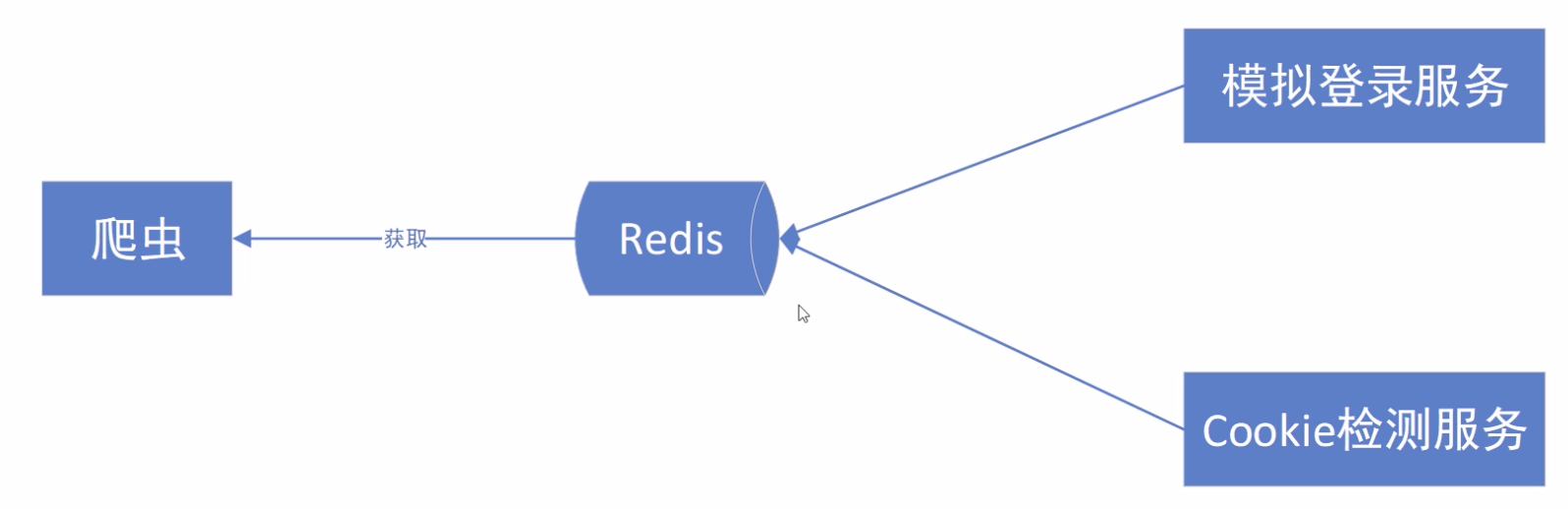
首先,最基本的功能是通过模拟登录服务获取cookie。
其次,因为cookie正常情况下都有过期时间,为保证cookie池系统独立稳定运行,需要实现Cookie检测服务。
然后,通过检测的有效cookie存入Redis中,以备爬虫运行时获取。
实现cookie池系统面临的挑战
- 如何发现cookie池不够用。
- 各个网站的cookie如何分开管理,代码如何更好的分离。
- 如何及时发现某个cookie失效了。
- 如何保证新加入的网站快速接入cookie池系统。
- 如何统一管理配置。
只抛出问题不解决问题不是一个好习惯,今日限于篇幅只是做简要介绍,后续实现改日再写。