定义
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。
Apache Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
Kafka是一个分布式的基于发布/订阅模式的消息队列 (Message Queue),应用于大数据实时处理领域,主要应用场景是:日志收集系统和消息系统。
Kafka组成
特点:三方分布式,灵活扩缩容
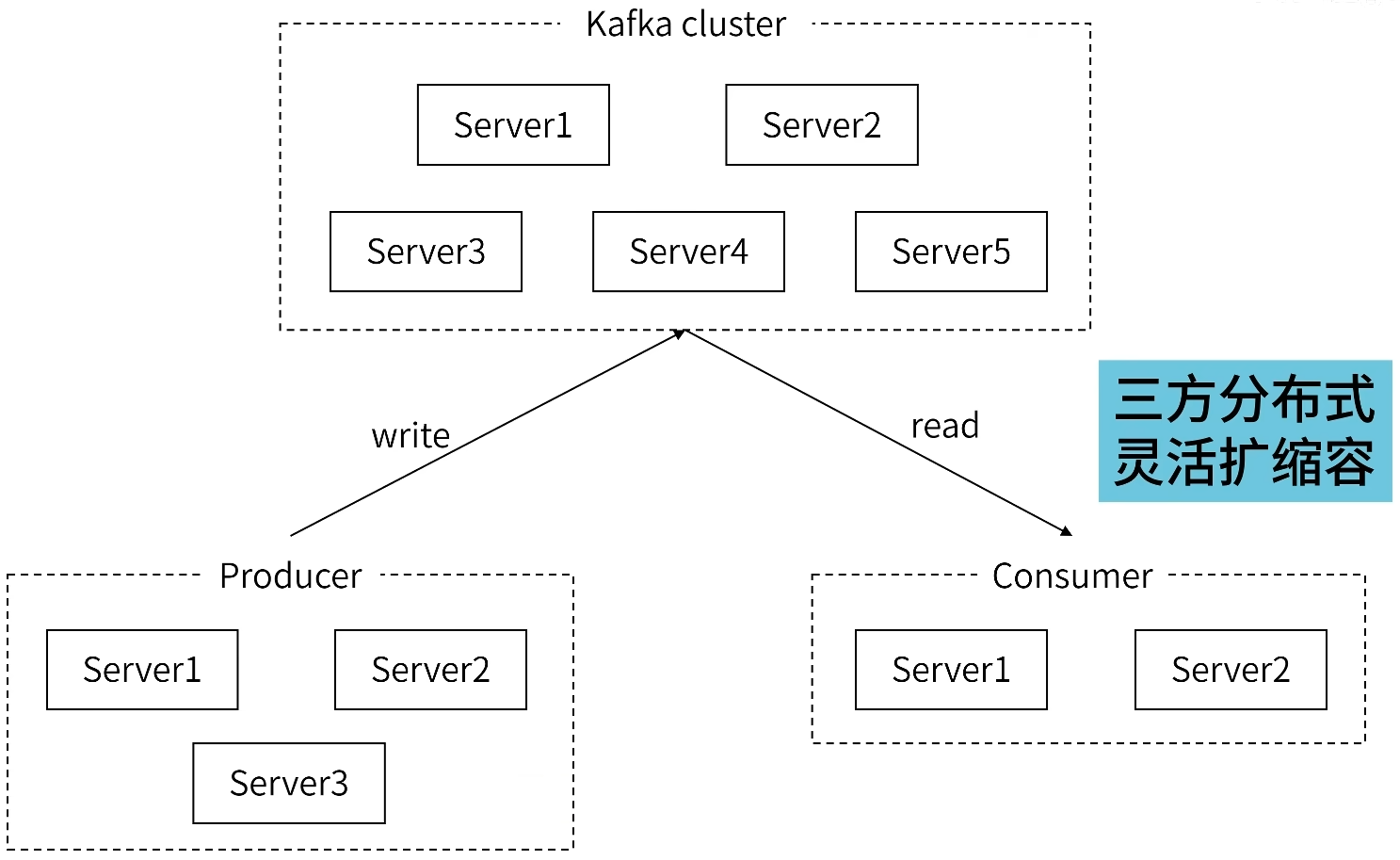
Kafka Cluster, Producer, Consumer
消息从生产方产生,发给kafka集群
消费者准备好,由kafka把消息推送给消费者
Kafka Cluster
Kafka集群搭建要借助与Zookeeper来存储节点的元数据信息,从而达到消息代理(Broker)的高可用。
一台服务器上可以起一个kafka实例,也可以启多个kafka实例。
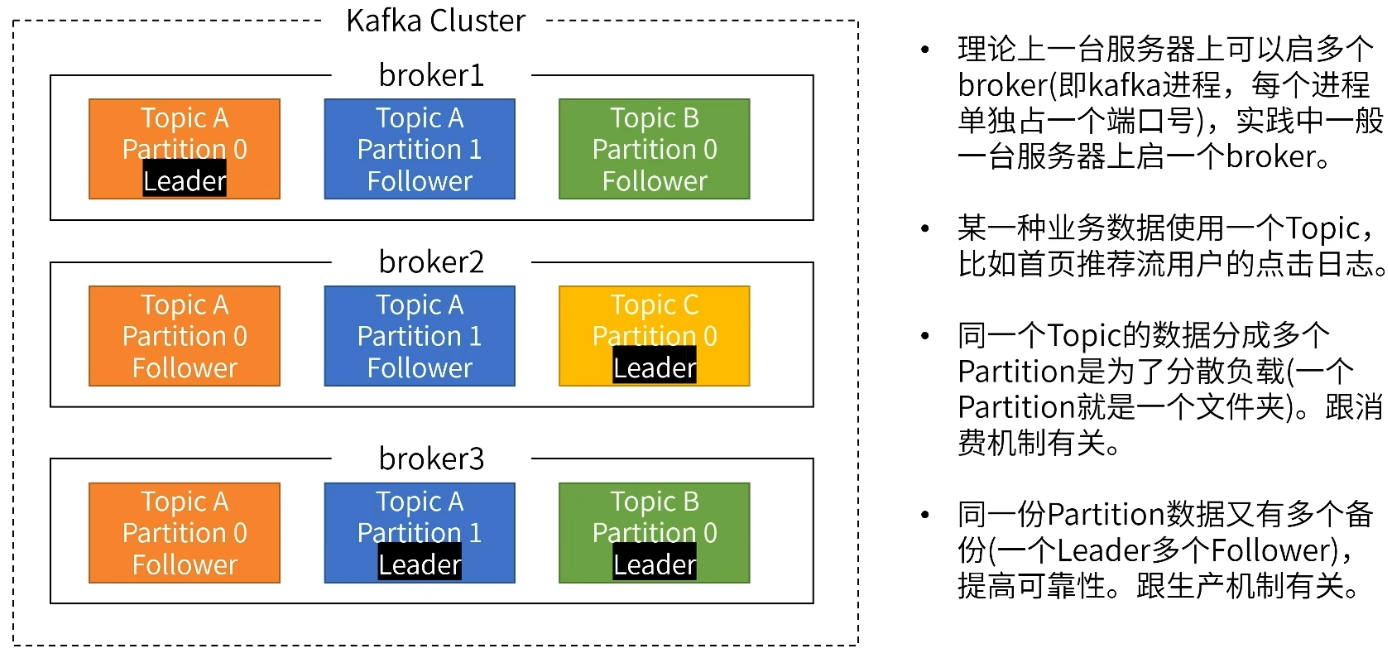
划分partition是为了增加消费方的吞吐量,同时也会带来生产方写入吞吐量的提升。
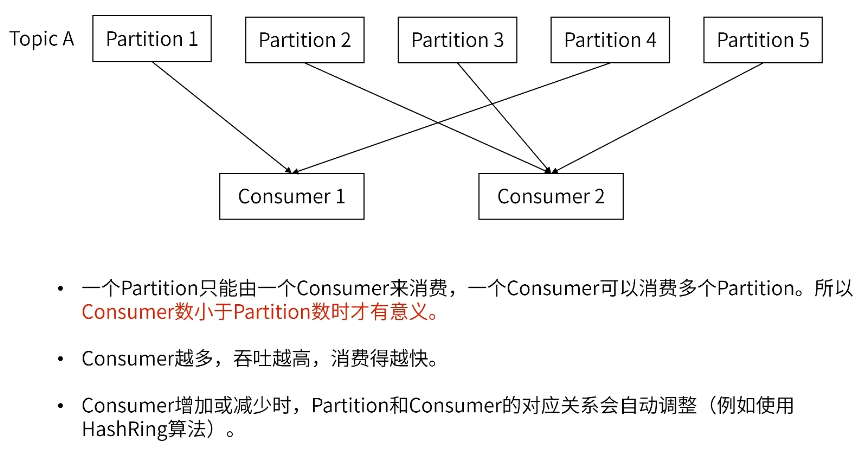
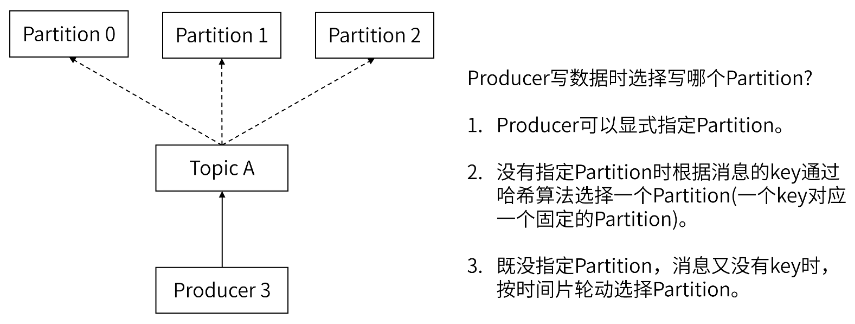
每个Kafka Topic(主题)都可以设置指定数量的Partition(分区),消息会根据算法分配到不同的Partition(分区)中。 同组内,一个Partition只能由一个Consumer来消费,一个Consumer可以消费多个Partition。 如果Partition不可用,会导致数据丢失。故Kafka通过分区副本来保证分区的高可用。
Partition数 > Consumer数
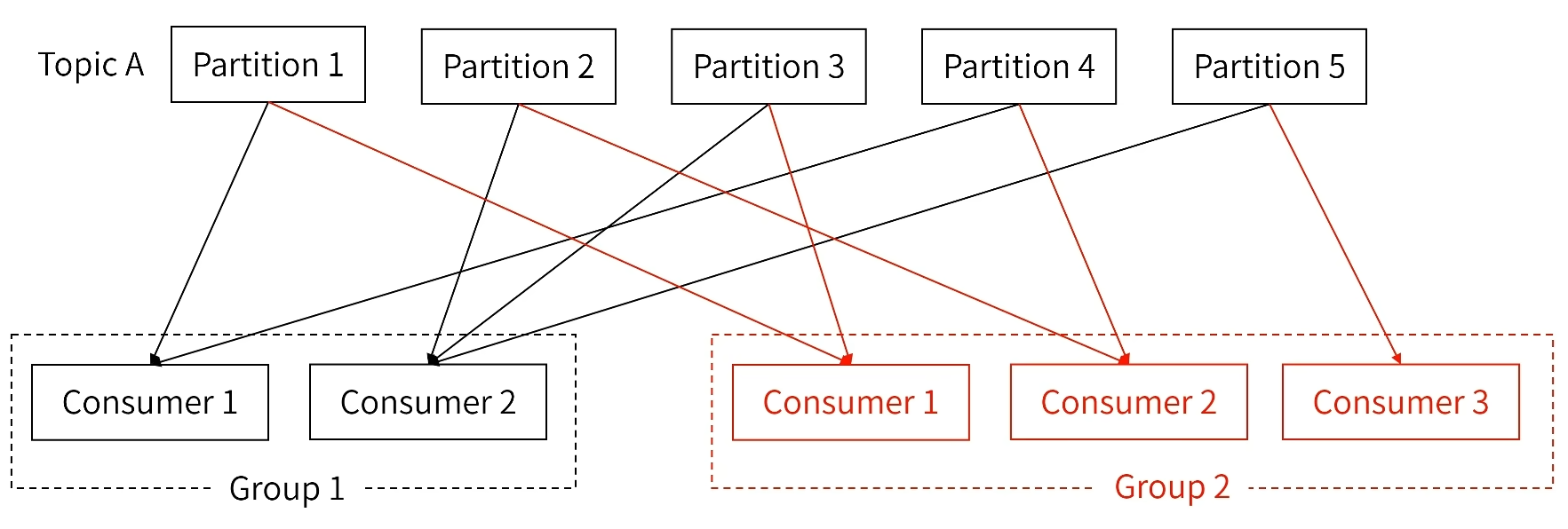
- 一个Group对应一个使用数据的业务方。(如:首页推荐给用户的商品点击日志,可能推荐算法团队需要消费,广告团队也需要消费)
- 每个Group消费一份完整的Topic数据。(如:一个Topic有5个Partition,Group1可以消费5个Partition,Group2也可以消费5个Partition)
- 同一个consumer group下订阅的topic的每个分区只能分配给这个consumer group下的一个consumer。(如:Consumer1消费Partition1和Partition4,Consumer2消费Partition2、Partition3、Partition5)
offset

- 不同Partition的消息根据offset无法比较新旧。
- Consumer重启时kafka根据该Group上一次commit的最大offset,决定从哪个地方开始消费。
生产方Partition写入
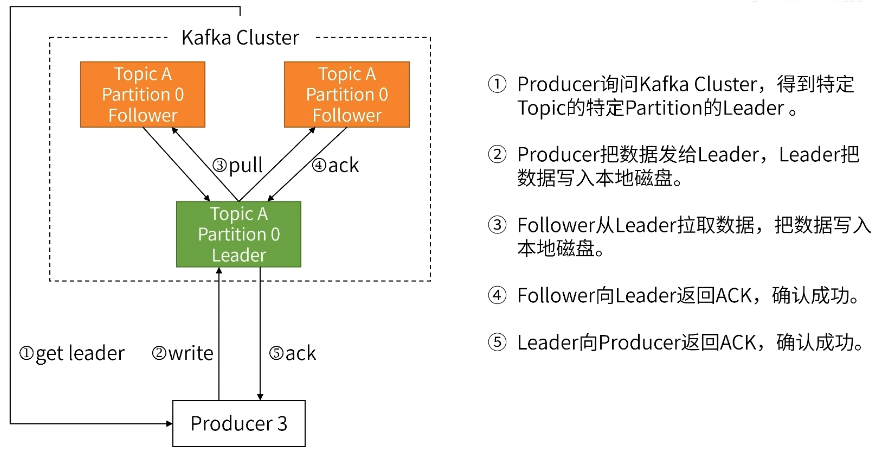
是否等待返回ack可以设置,可以只接收leader的ack,也可以不需要等任何ack返回。
Kafka主要设计目标
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展
Kafka高频命令
查询Kakfa的版本
目前是没有自带版本查询命令的,可以直接查看jar包的版本
1.进到kafka的安装目录
2.执行shell查询命令
find ./libs/ -name \*kafka_\* | head -1 | grep -o '\kafka[^\n]*'
kafka_2.11-1.1.1-javadoc.jar.asc
其中,2.11为scala版本,1.1.1为kafka版本。
常见Kafka问题
什么是消费者组 (Consumer Group)
什么是consumer group? 一言以蔽之,consumer group是kafka提供的可扩展且具有容错性的消费者机制。
既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。
组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。
当然,每个分区只能由同一个消费组内的一个consumer来消费。
消费者组 (Consumer Group)的三个特性: - consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程 - group.id是一个字符串,唯一标识一个consumer group - consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
消费者位置(consumer position)
消费者在消费的过程中需要记录自己消费了多少数据,即消费位置信息。在Kafka中这个位置信息有个专门的术语:位移(offset)。
Kafka保存位移的机制:每个consumer group保存自己的位移信息,那么只需要简单的一个整数表示位置就够了;同时可以引入checkpoint机制定期持久化,简化了应答机制的实现。
kafka是如何保证消息不被重复消费的
1.kafka自带的消费机制
kafka有个offset的概念,当每个消息被写进去后,都有一个offset,代表他的序号,然后consumer消费该数据之后,隔一段时间,会把自己消费过的消息的offset提交一下,代表我已经消费过了。下次我要是重启,就会继续从上次消费到的offset来继续消费。
但是当我们直接kill进程了,再重启。这会导致consumer有些消息处理了,但是没来得及提交offset。等重启之后,少数消息就会再次消费一次。
其他MQ也会有这种重复消费的问题,那么针对这种问题,我们需要从业务角度,考虑它的幂等性。
2.通过保证消息队列消费的幂等性来保证
举个例子,当消费一条消息时就往数据库插入一条数据。如何保证重复消费也插入一条数据呢?
那么我们就需要从幂等性角度考虑了。幂等性,我通俗点说,就一个数据,或者一个请求,无论来多次,对应的数据都不会改变的,不能出错。
3.怎么保证消息队列消费的幂等性?
我们需要结合业务来思考,比如下面的例子:
1.比如某个数据要写库,你先根据主键查一下,如果数据有了,就别插入了,update一下好吧
2.比如是写redis,那没问题了,反正每次都是set,天然幂等性
3.对于消息,我们可以建个表(专门存储消息消费记录)
- 生产者,发送消息前判断库中是否有记录(有记录说明已发送),没有记录,先入库,状态为待消费,然后发送消息并把主键id带上。
- 消费者,接收消息,通过主键ID查询记录表,判断消息状态是否已消费。若没消费过,则处理消息,处理完后,更新消息记录的状态为已消费。
推荐阅读
- Apache Kafka Quickstart
- Kafka权威指南 - 现在看这本书版本太旧了。
- 大数据技术之Kafka
- Kafka学习之路
- 如何搞定Kafka重复消费?
- 图说kafka
- golang操作kafka - 主要讲kafka-go